
Abstract.
본 논문은 딥러닝은 보통 많은 양의 정답 데이터가 필요하다는 통념에서 시작해, 적은 수의 라벨 이미지로도 의료 영상 분할을 잘 학습시키기 위한 네트워크 구조와 학습 전략을 제시합니다. 핵심은 데이터 증강으로 제한된 라벨 데이터를 효율적으로 쓰는 것이고, 구조적으로는 문맥을 넓게 잡는 contracting path와 픽셀 단위 위치를 정밀하게 복원하는 대칭 expanding path를 결합해 분류와 localization을 동시에 해결한다는 점입니다.
Introduction.
본 논문은 최근 2년간 CNN이 시각 인식 테스크에서 SOTA를 달성한 건 ImageNet과 같은 대규모 데이터와 큰 모델을 감당할 수 있었기 때문이라 말합니다. 그러나 의료 영상의 경우, 이미지 1장에 대한 분류가 아니라 localization이 포함되는 각 픽셀에 클래스를 붙이는 분할이며, 수천장의 라벨 데이터를 확보하기 어렵습니다.
기존 접근으로는 슬라이딩 윈도우(패치 단위) 예측이 대표적이었는데, 패치를 입력으로 넣어 분류하는 방식입니다. 이는 (1) 패치마다 네트워크를 반복 실행해야해 느리고 중복 계산이 크며, (2) context를 늘리려면 더 큰 패치와 더 많은 풀링이 필요해지져 정밀한 localization을 파악하기 어렵고, 반대로 작은 패치의 경우 localization은 좋지만 context가 부족해지는 trade-off가 생긴다는 한계점을 제시합니다.
그리해 본 논문은 FCN 계열을 기반으로 한, Contracting Path(문맥) + Expanding Path(정밀 위치 복원)을 대칭적으로 이어붙인 U자 구조를 제안합니다.
여기에 추가로
(a) 업샘플링 쪽에서도 채널 수를 유지해 고해상도 층까지 context를 전달할 수 있게하고,
(b) 패딩 없이 Conv를 적용해, 가장자리처럼 context가 부족한 픽셀은 충분히 주변 정보를 본 후에 신뢰 가능한 출력만 포함시키며,
(c) 큰 이미지를 다루기 위해 overlap-tile + 경계 mirror 보완으로 타일 경계에서 예측이 이상해지는 문제를 줄였다.
또한 의료 영상의 라벨 데이터 부족을 위해, elastic deformation 중심의 데이터 증강을 강조하고, 세포처럼 클래스 객체가 붙어있는 문제를 위해 분리 배경에 큰 가중치를 주는 weighted loss를 제안하였다.
Network Architecture.

U-Net의 아키텍처는 좌측의 Contracting Path와 우측의 Expansive Path가 대칭으로 붙은 U자 형태로 설계되어, 한쪽에서는 context을 넓게 잡고 다른 쪽에서는 픽셀 단위 위치를 정밀하게 복원하도록 만든 구조입니다.

Contracting Path는 일반적인 CNN처럼 3×3 컨볼루션(패딩 없는 unpadded) 2회 + ReLU를 반복하고, 그 뒤에 2×2 max pooling(stride 2)으로 다운샘플링하면서 내려가며, 내려갈 때마다 feature 채널 수를 2배로 증가시킵니다.


반대로 Expansive Path는 각 단계에서 feature map을 업샘플링한 뒤 2×2 up-convolution로 채널 수를 절반으로 줄이고, Contracting Path의 같은 해상도에서 가져온 feature map을 crop해서(concatenation 전에 크기 맞춤) concat한 다음, 다시 3×3 컨볼루션 2회 + ReLU을 적용한다.
여기서 crop이 필요한 이유는 U-Net이 각 컨볼루션에서 패딩을 적용하지 않기에 가장자리 픽셀이 계속 깎이기 때문이고, 그 결과 출력 segmentation map은 입력에서 충분한 문맥이 확보된 픽셀만 포함하도록 설계된다.
마지막에는 1×1 컨볼루션으로 각 픽셀의 feature 벡터를 원하는 클래스 수로 매핑하며, 전체적으로 fully connected layer 없이 동작하는 순수 Conv 기반 네트워크이고, 총 23개의 Conv layer로 구성된다.
- Overlap-Tile Input
U-Net은 fully convolutional network 구조이기에 입력 이미지 크기에 제약이 없다. 따라서 크기가 큰 이미지의 경우 overlap-tile을 사용한다.
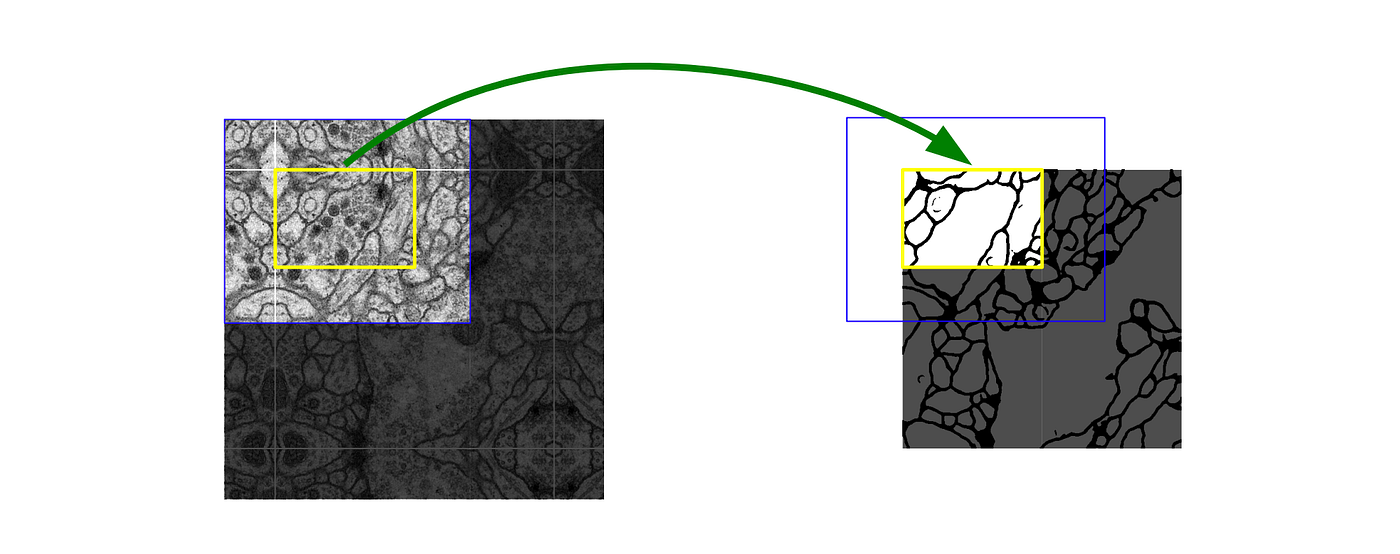
위 이미지의 파란 영역과 같이, 이미지를 타일로 나눠 입력으로 사용한다. 파란 영역의 이미지를 입력하면 노란 영역의 Segmentation 결과를 얻는 것이다.
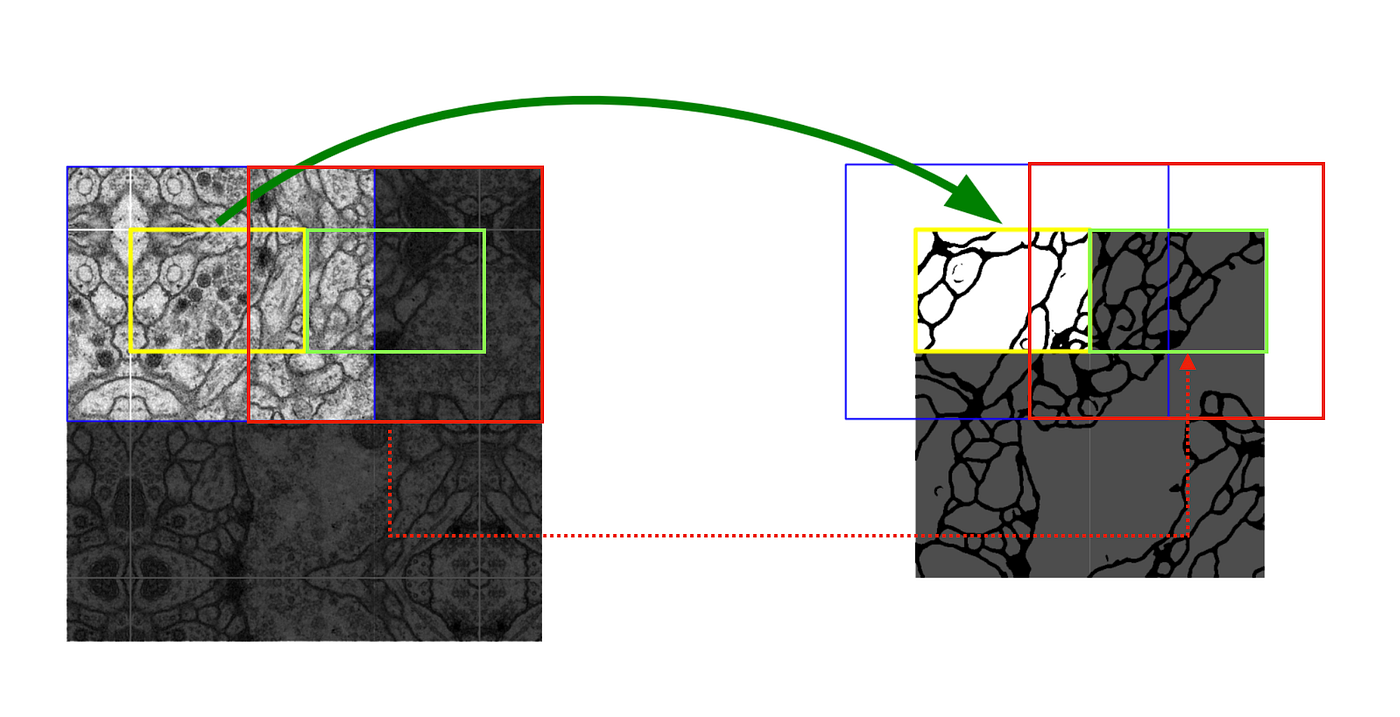
빨간 영역과 같이, 다음 타일에 대한 Segmentation을 얻기 위해서는 이전 입력의 일부분이 포함되어야한다.

이미지 경계 부분의 segmentation을 위해 0이나 임의 패딩값을 사용하지 않고, 이미지의 경계 부분의 미러링을 이용한 Mirroring Extrapolatation을 사용한다.
- Touching cells separation
세포 분할(Segmentation) 작업에서 주요한 과제 중 하나는 동일한 클래스의 접촉 개체를 분리하는 것이다.

겹쳐 있는 세포 사이의 경계부분을 분리하기 위해 사전 학습된 가중치 맵을 사용한다. 이미지 c, d 와 같이 각 세포 사이의 경계를 포착할 수 있어야하기 때문이다.
이를 위해 각각의 세포가 구분되어있는 GT의 모든 픽셀에 대해 (1) 가장 가까운 세포 경계까지의 거리와 (2) 두 번째로 가까운 세포 경계까지의 거리를 계산한다. 세포와 세포 사이에 있는 분리선 픽셀은 d1과 d2 모두 작을 것이기에 d1+d2가 매우 작아진다는 것이다. 따라서, 위 식에서 d1+d2가 작으면 값이 거의 w0에 가깝게 커지게 되고, 다른 세포 경계가 멀어 d2가 커지는 경우라면 지수항이 거의 0이 된다. 즉, 세포와 세포 사이의 분리선만 가중치가 커지는 것이다. 또한 wc(x)는 클래스 빈도 불균형을 보정하기 위한 것으로, 배경 픽셀만 너무 많을 경우 그쪽으로 학습이 치우치지 않게 하기 위함이다.




Training.
U-Net은 SGD로 학습한다. 이때 논문은 패딩을 두지 않는 valid convolution을 사용하기 때문에, 네트워크를 통과할수록 출력 맵의 크기가 입력보다 줄어든다. 따라서 입력을 작은 타일로 잘라 학습하게 된다면 문맥이 부족한 가장자리 영역이 크게 생기고, 결과적으로 실제로 학습에 기여하는 유효한 픽셀 비율이 낮아지게 된다. 이러한 비효율을 줄이기 위해 저자들은 GPU 메모리를 배치 수를 늘리는 데 쓰기보다, 한 번에 더 큰 타일을 넣어 더 많은 유효 픽셀을 확보한다. 그리해 배치 크기는 1로 셋팅된다.
다만 배치가 1이면 각 업데이트가 단일 샘플의 기울기에 크게 영향을 받기 때문에 학습이 흔들릴 수 있다. 이를 완화하기 위해 모멘텀을 0.99로 크게 설정해, 현재 샘플의 기울기만 따라가기보다 이전 업데이트 방향을 강하게 누적시키도록했다.


Loss는 마지막 feature map에 대해 픽셀 단위로 softmax와 cross entropy를 적용하는데, 중요한 점은 모든 픽셀을 똑같이 보지 않는다는 것이다. 클래스 빈도 불균형을 보정하고, 특히 서로 붙어 있는 객체를 잘 분리하기 위해 위에서 설명한 픽셀별 가중치 맵 w(x)를 미리 계산해 loss에 곱한다.
또한 딥 네트워크에서는 초기화가 중요하다. 본 논문에서는 He 초기화(표준편차가 √(2/N)인 가우시안 샘플링)를 사용하며, 위치/회전/변형/명암 변화에 대한 강건성이 필요하다는 점을 언급하며 데이터 증강을 사용했다고 말한다.
단순한 회전/이동 데이터 증강만으로는 현미경 이미지에서 흔히 보이는 조직의 휘어짐과 늘어남을 충분히 재현하기 어렵기에, 논문은 random elastic deformation을 특히 강조한다. 구현 방식은 이미지 위에 3×3 기준점 9개를 놓고 각 그리드 점에 랜덤 변위 벡터를 준 뒤, 그 변위를 bicubic interpolation으로 픽셀 단위까지 부드럽게 펼쳐서 이미지 전체가 자연스럽게 휘어지도록 만드는 것이다(변위는 표준편차 10px의 가우시안에서 샘플링).
이렇게 생성된 데이터들을 계속 보여주게 된다면, 모델은 적은 정답 이미지로도 변형에 대한 불변성과 강건성을 학습할 수 있다. 더불어 논문은 수축 경로 끝부분에 dropout을 넣어 학습 중 네트워크가 매번 조금씩 다른 서브모델처럼 동작하게 만들어 추가적인 데이터 증강 효과까지 얻는다.
Experiments.
U-Net은 3개 분할 데이터셋에서 성능을 검증했다.

첫 번째는 EM 기반 neuronal structure segmentation으로, EM Segmentation Challenge에서 Warping Error 최고 성능을 기록했다.


두 번째는 ISBI Cell Tracking Challenge의 PhC-U373 세포 분할로 1위를 했고, 세 번째 DIC-HeLa에서도 2위와 큰 격차로 우승하며 강한 일반화 성능을 보여줬다.
Conclusion.
U-Net이 서로 다른 형태의 생의학 영상 분할 과제들에서도 일관되게 높은 성능을 낸다는 점을 핵심으로 정리한다. 특히 라벨 데이터가 매우 제한적인 상황에서도 elastic deformation 중심의 강한 데이터 증강 덕분에 아주 적은 주석 이미지로 학습이 가능했고, 학습 시간도 6GB NVidia Titan GPU 기준 약 10시간으로 현실적인 수준이라고 명시한다. 또한 저자들은 Caffe 기반 구현과 학습된 네트워크를 공개하며, 이 구조가 특정 데이터셋에만 특화된 트릭이 아니라 더 많은 분할 문제에 쉽게 확장 적용될 수 있다는 말로 마무리한다.
[참고]
'ML&DL > 논문리뷰' 카테고리의 다른 글
| Transformer: Attention Is All You Need (0) | 2026.01.18 |
|---|---|
| Mask R-CNN (0) | 2026.01.03 |
| Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks (0) | 2025.12.29 |
| VAE: Auto-Encoding Variational Bayes (0) | 2025.12.23 |
| StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2025.11.27 |